
FlashInfer 0.2 - Efficient and Customizable Kernels for LLM Inference Serving

Generated by DALL-E
After four months of development, we are thrilled to announce the release of FlashInfer 0.2. This major update introduces performance improvements, enhanced flexibility, and critical bug fixes. Key highlights of this release include:
- Faster sparse (page) attention with FlashAttention-3 template
- JIT compilation for attention variants
- Support for Multi-head Latent Attention (MLA) decoding
FlashAttention-3 Template with Block/Vector-Sparsity
FlashAttention-3 brings a breakthrough optimization for Hopper GPUs by cleverly overlapping softmax and matrix multiplication. FlashInfer 0.2 integrates FA-3 templates, achieving significant improvements in prefill attention performance on Hopper architecture.
Flexible Block-Sparsity and Vector-Sparsity
FlashInfer’s standout feature is its highly flexible block-sparse FlashAttention implementation, supporting any block size configuration. Our PageAttention operators are implemented as block-sparse attention kernels, where page_size specifies the block’s column count. At its finest granularity, FlashInfer supports vector-sparsity1 (page_size=1), allowing for precise memory management (used in sglang) and efficient KV-Cache token pruning.
By leveraging CuTe’s CustomStride and ComposedLayout abstractions, we have extended vector-sparsity to FlashAttention-3. Inspired by CUTLASS’s gather/scatter convolution, this was achieved through a simple modification to the producer’s memory loading module.
Performance Benchmark
We compared two attention implementations: PageAttention with page_size=1 2 (use vector-sparse attention implementation) and variable-length dense attention 3, benchmarking them under identical problem sizes across both FA-2 (v0.1.*) and FA-3 (v0.2) backends. Benchmarks used head_dim=128, causal=True, varying batch sizes (B) and sequence lengths (L) with Gaussian-initialized input Q/K/V tensors.
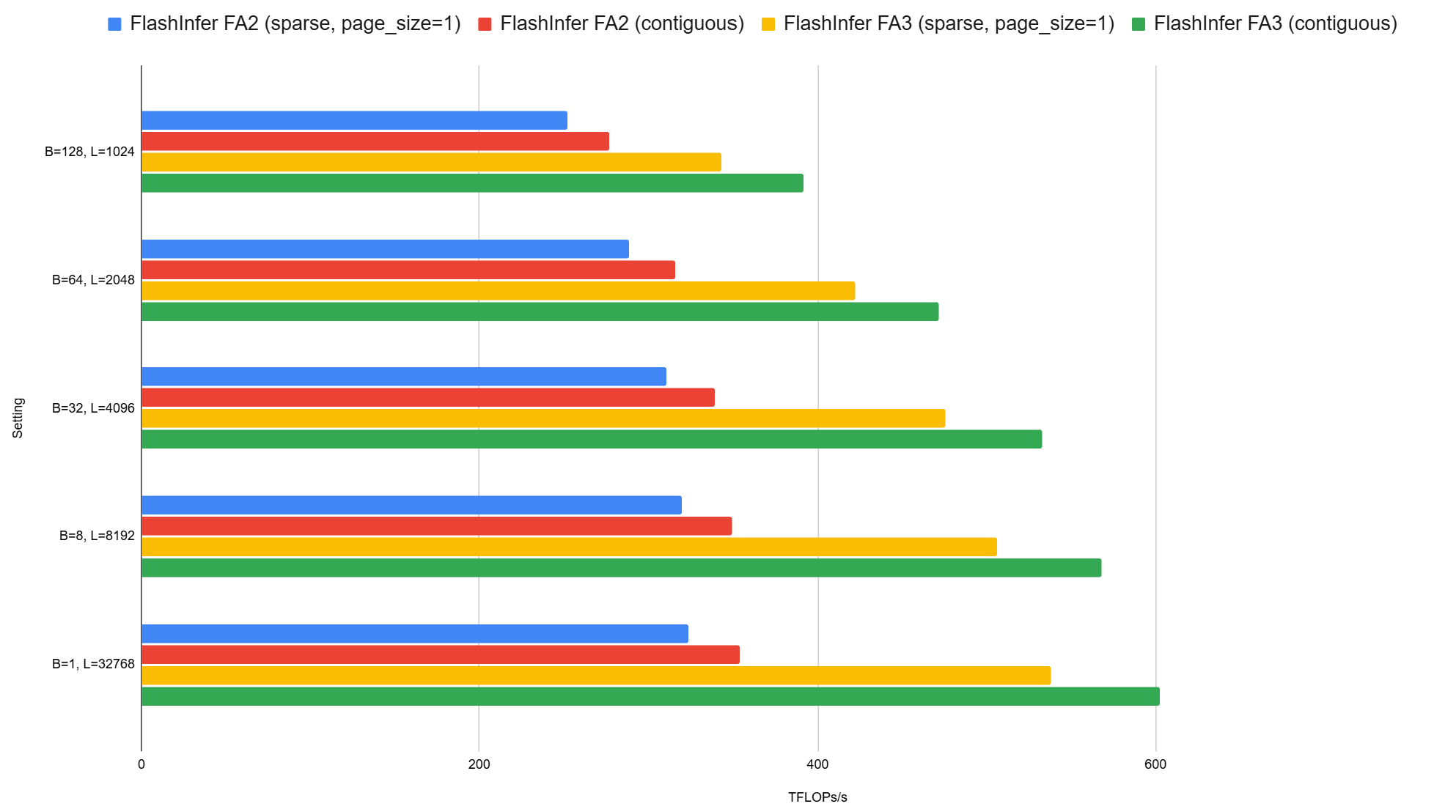
Performance comparison between dense/vector-sparse attention on FA-2 and FA-3 templates on H100 SXM5, compiled with CUDA 12.4. y-axis: different settings, x-axis: achieved TFLOPs/s
Results: Vector-sparse attention achieves 90% of dense attention’s throughput under identical conditions. The FA-3 backend consistently outperforms FA-2. Thanks to FlashInfer’s stable API, upgrading from FA-2 to FA-3 requires no code changes—just install FlashInfer 0.2. The reference benchmark script for reproducing these results is available here.
JIT Compilation for Attention Customization
Inspired by FlexAttention, FlashInfer 0.2 introduces customizable programming interface to compile different attention variants. We designed a modularized attention template in CUDA/Cutlass. Users can define custom attention variants by specifying functors such as LogitsTransform/QueryTransform/etc in an attention variant class. The class string will specialize our pre-defined Jinja templates and FlashInfer uses PyTorch’s JIT load function to compile and cache these kernels. New variants like FlashSigmoid can be implemented with minimal code. See our JIT examples for more cases.

Left: JIT workflow in FlashInfer. Right: Compile new attention variants.
In addition to supporting new attention variants, other benefits of supporting JIT in FlashInfer include:
- Reduced wheel size: The binary size of FlashInfer increases exponentially in recently releases because we pre-compile combination of all attention variants. We have to reduce specialization to make wheel size managable which harms kernel performance (as observed in #602, FlashInfer v0.1.6’s prefill performance is even worse than FlashInfer v0.1.1 because we move compile-time parameters to runtime which harms performance). FlashInfer v0.2 address the issue by just pre-compile a subset of core kernels ahead-of-time, while leaving most of the attention variants JIT compiled.
- Light development: No need to reinstall FlashInfer for minor CUDA changes, by installing FlashInfer in JIT Mode.
We have optimized the speed of JIT compilation by minimizing header dependencies and utilizing split compilation. As a result, all kernels for Llama models can be JIT-compiled within 15 seconds on server-grade CPUs. For more details, check out our JIT warmup scripts.
Fused Multi-head Latent Attention (MLA) Decoding Kernel
Multi-head Latent Attention (MLA), introduced in Deepseek v2, compresses the KV-Cache by projecting it into low-rank matrices. Achieving high throughput for MLA is challenging due to a lack of optimized kernels. FlashInfer community recently implemented an fused kernel with the Matrix Absorption trick, improving memory efficiency. See #551 for detailed explanation.
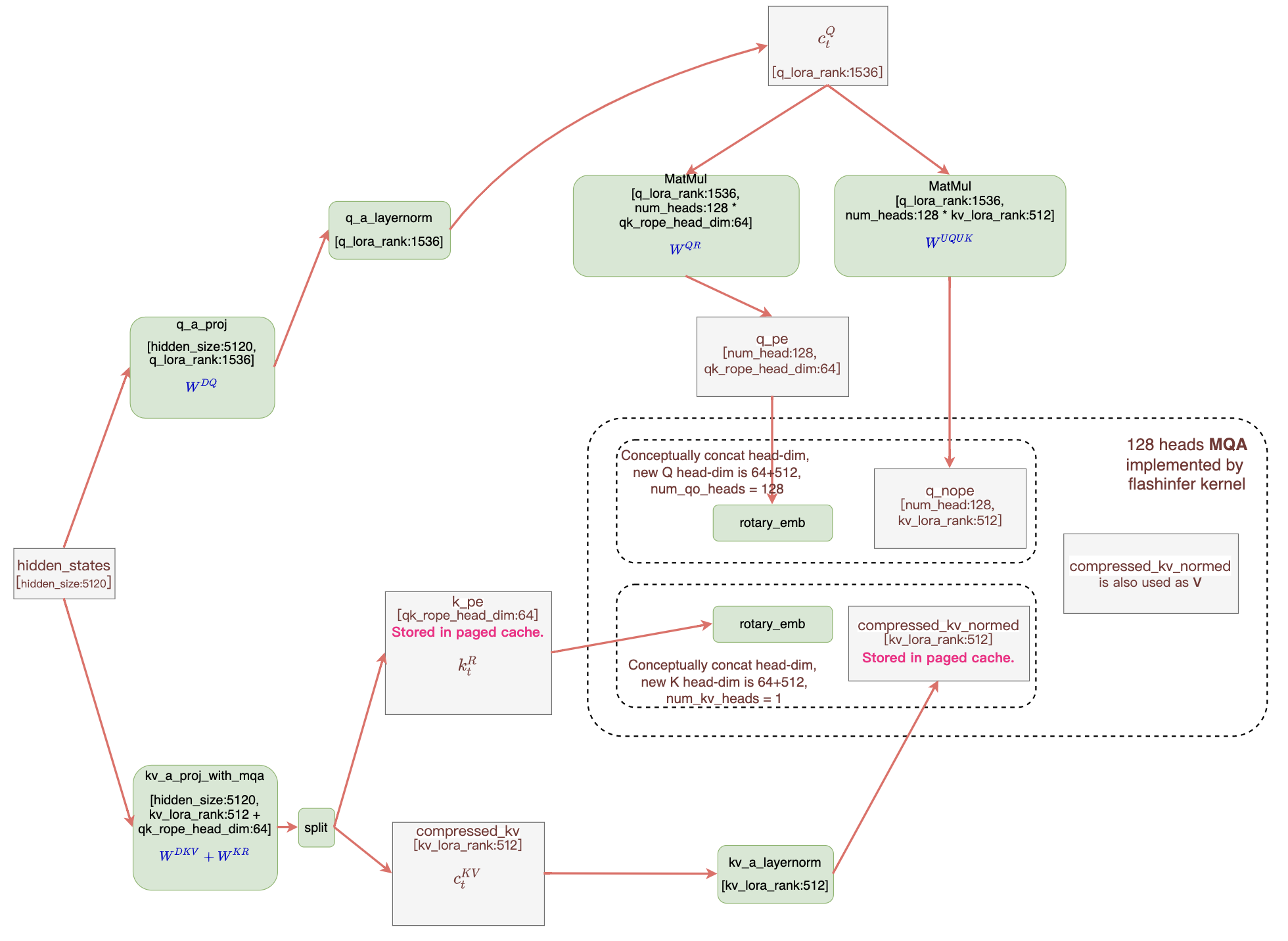
MLA decode kernel workflow in FlashInfer
Future plans include accelerating MLA decoding with Tensor Cores, benefiting speculative decoding.
CUDAGraph Compatibility for Variable-Length Inputs
FlashInfer 0.2 fixes prefill attention’s incompatibility with CUDAGraph when query lengths vary during capture and replay stages, by accurately estimating upper resource bounds. CUDAGraphs now can be used to accelerate speculative decoding and chunked-prefil workloads with FlashInfer kernels.
torch.compile Compatibility
FlashInfer 0.2 adheres to the PyTorch Custom Operators Standard, ensuring compatibility with torch.compile.
Packaging and CI/CD
We now provide nightly builds so users can test the latest features without waiting for stable releases.
Other Notable Improvements
FusedAddRMSNorm Fix
Fixed numerical issues in FusedAddRMSNorm, which may cause bad outputs for some models.
Cutlass’s SM90 Grouped-GEMM Integration
We integrated Cutlass 3.5 SM90 Grouped-GEMM into our SegmentGEMM API, accelerating LoRA and MoE serving.
Non-Contiguous KV-Cache Support
KV-Cache can now utilize non-contiguous storage layouts, improving support for offloading.
Faster plan Functions
plan functions now use non-blocking host-to-device memory transfers, improving performance. After FlashInfer v0.2, it’s encouraged to pass host tensors instead of device tensors to reduce synchronization in the plan function.
KV-Cache Append Optimization
KV-Cache append throughput for small batch sizes was improved by parallelizing per element instead of per request. A new API, get_batch_indices_positions, supports this. Note that we made some breaking changes to this API to accomodate different parallelization mode. See our benchmark for the new API usage.
Standardized RoPE Interface
We standardized the RoPE interface to align with other frameworks. FlashInfer adopted fp32 sin/cos computations to avoid numerical issues.
Roadmap
We appreciate the community’s love and support. To enhance transparency, we’ve published our development roadmap, where you can provide feedback and influence FlashInfer’s future.
Community Contributions
The number of contributors grew from 41 to 52 since v0.1.6. We thank the following developers for their contributions:
- @yzh119: JIT, FA-3 Template, and others
- @abcdabcd987: torch.compile support, packaging
- @nandor: Variable-length CUDAGraph support
- @ur4t: Packaging, CI/CD
- @zhyncs: Nightly builds, CI/CD
- @tsu-bin: MLA decoding
- @xslingcn: Cutlass Grouped-GEMM
- @yuxianq: JIT, bug fixes
- @LinHeLurking: Non-contiguous KV-Cache
- @Abatom: FusedAddRMSNorm fix
- @jeejeelee: Grouped-GEMM bug fixes
- @mvpatel: Faster
planfunctions - @Ubospica: Pre-commit setup
- @dc3671: Improved unit tests
- @Pzzzzz5142: JIT compilation fix
- @reyoung: Bug fixes
- @xiezhq-hermann: ARM compilation fixes
- @Bruce-Lee-LY: Performance optimizations
- @francheez: Typo fixes
Comments