
Sorting-Free GPU Kernels for LLM Sampling
Background
As vocabulary sizes grow larger in Large Language Models (LLMs), categorical sampling (token selection) has emerged as a significant performance bottleneck in LLM inference serving. The sampling operators in FlashInfer were first introduced in v0.0.5, and since then, the FlashInfer team has continuously improved their robustness and performance. In this blog post, we’ll explore the algorithms and implementation details behind FlashInfer’s sampling operators.
LLM Sampling
Categorical Sampling is the process that picks a specific next token from model output probabilities (over the vocabulary). In practice, filtering is applied before sampling to pass tokens with negligible probability, control generation behaviors, and enforce minimum probabilities, such as Top-P, Top-K, or Min-P thresholds:
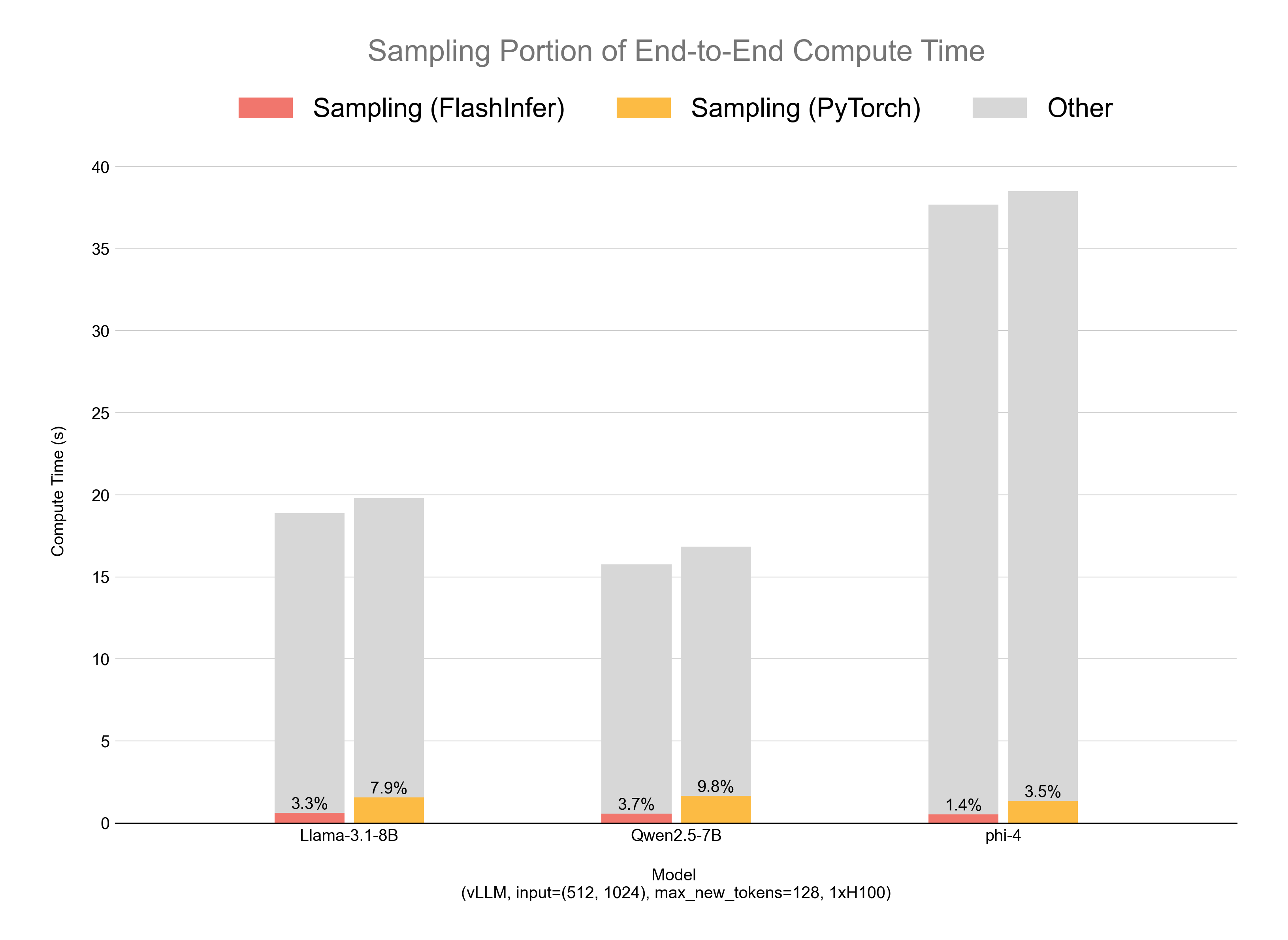
Figure 1: The compute time break down highlighting the sampling process. In the vLLM 1xH100 configuration, our kernels reduce the overall sampling time by more than 50% across all three models.
-
Top-K
Top-K sampling keeps only the $K$ tokens with the highest probabilities at each generation step. For example, if $K=50$, the model will ignore all tokens outside the top 50 likely candidates.
-
Top-P rather keeps the smallest set of tokens whose cumulative probability just exceeds a threshold $P$. For example, if $P=0.9$, you accumulate token probabilities in descending order until their sum is at least 0.9.
-
Min-p filters out all tokens below a minimum threashold $p_\text{base} \times p_\text{max}$, where $p_\text{base}$ is parameter and $p_\text{max}$ is the largest probability in the inputs. This helps eliminate extremely unlikely tokens while still respecting relative differences among the top candidates.
In practice, the combination of Top-K and Top-P filtering is popular and used as the standard setting for LLM sampling. This allows for finer-grained control over the generation process. For example if we use the Top-K first filtering, we first limit the token set to the Top-K highest probabilities, and then apply a Top-P cutoff to filter the tail portion within those $K$ tokens. 1
A PyTorch implementation of these samplers might look like this:
# vllm/vllm/model_executor/layers/sampler.py
def _apply_top_k_top_p(
logits: torch.Tensor,
p: torch.Tensor,
k: torch.Tensor,
) -> torch.Tensor:
logits_sort, logits_idx = logits.sort(dim=-1, descending=False)
# Apply top-k.
top_k_mask = logits_sort.size(1) - k.to(torch.long)
# Get all the top_k values.
top_k_mask = logits_sort.gather(1, top_k_mask.unsqueeze(dim=1))
top_k_mask = logits_sort < top_k_mask
logits_sort.masked_fill_(top_k_mask, -float("inf"))
# Apply top-p.
probs_sort = logits_sort.softmax(dim=-1)
probs_sum = probs_sort.cumsum(dim=-1)
top_p_mask = probs_sum <= 1 - p.unsqueeze(dim=1)
# at least one
top_p_mask[:, -1] = False
logits_sort.masked_fill_(top_p_mask, -float("inf"))
# Re-sort the probabilities.
src = torch.arange(logits_idx.shape[-1],
device=logits_idx.device).expand_as(logits_idx)
logits_idx_inv = torch.empty_like(logits_idx).scatter_(dim=-1,
index=logits_idx,
src=src)
logits = torch.gather(logits_sort, dim=-1, index=logits_idx_inv)
return logits
This code uses a combination of sorting, cumulative sums, and masking. While it is straightforward to follow, it induces performance bottleneck especially for large vocab size, because of the huge overhead of sorting.
In FlashInfer, we show that sampling under filtering can be done in sorting-free manner, and we introduce the Dual Pivot Rejection Sampling algorithm and design fused sampling kernel templates to fully leverage GPUs’ parallel computing capabilities, ultimately achieving logarithmic (in worst case) time complexity. In this blog, we’ll walk you through how we developed this algorithm integrating ideas from Inverse Sampling, Rejection Sampling, and final version of the algorithm with theorerical guarantee of convergence.
Algorithm
Inverse Transform Sampling
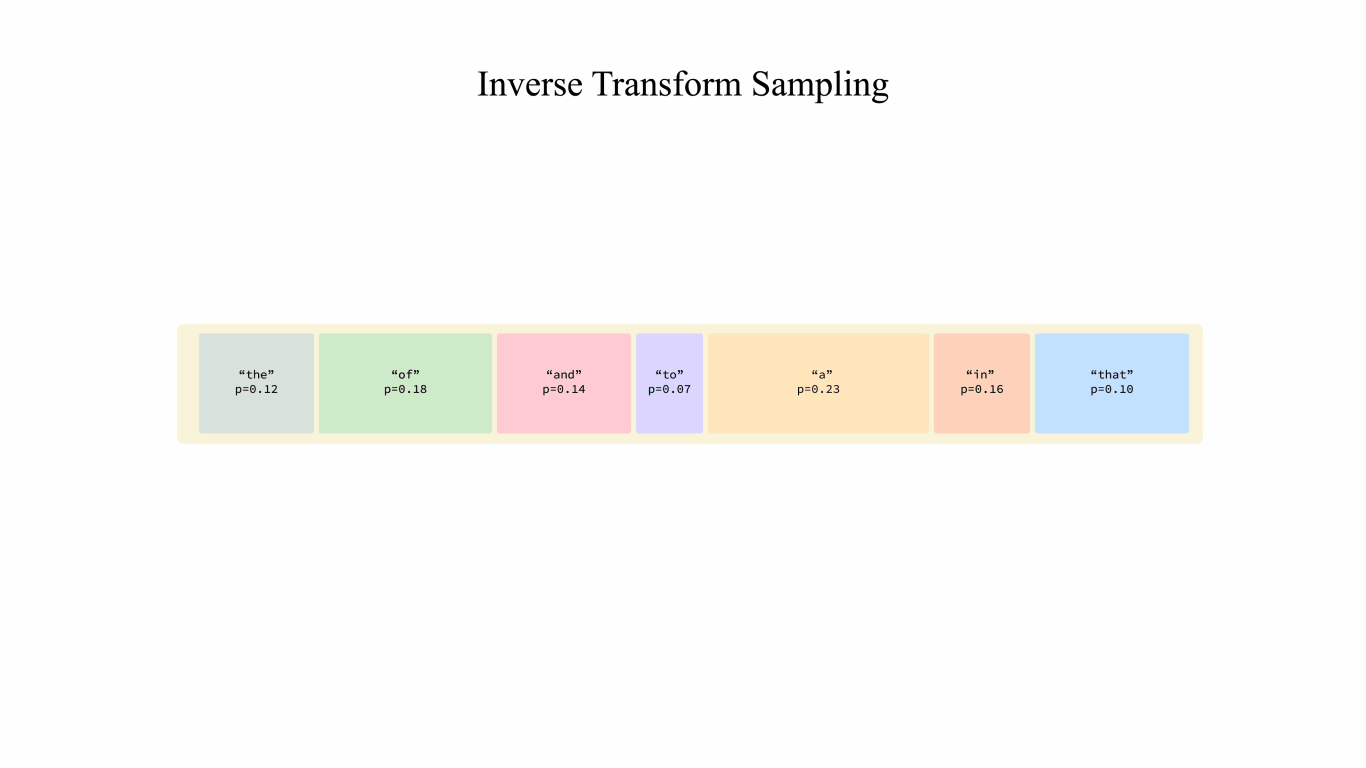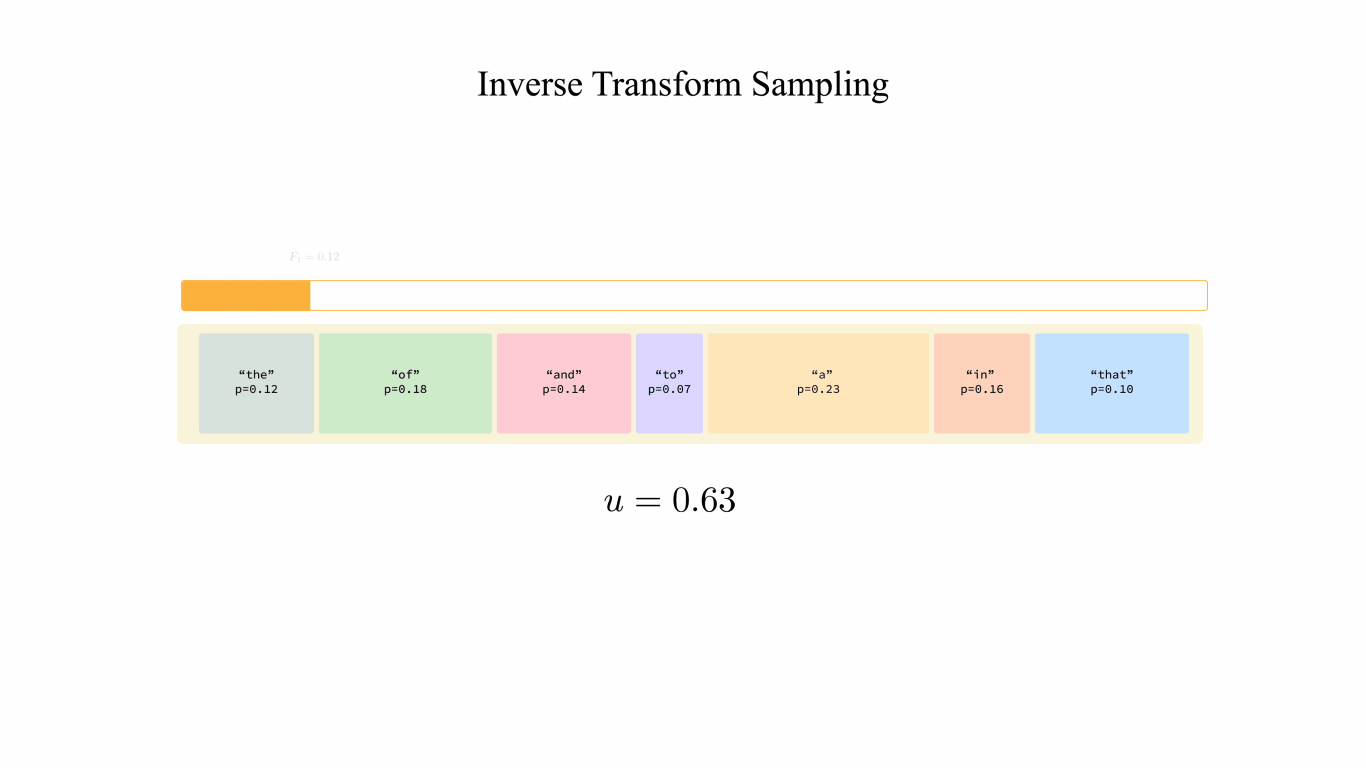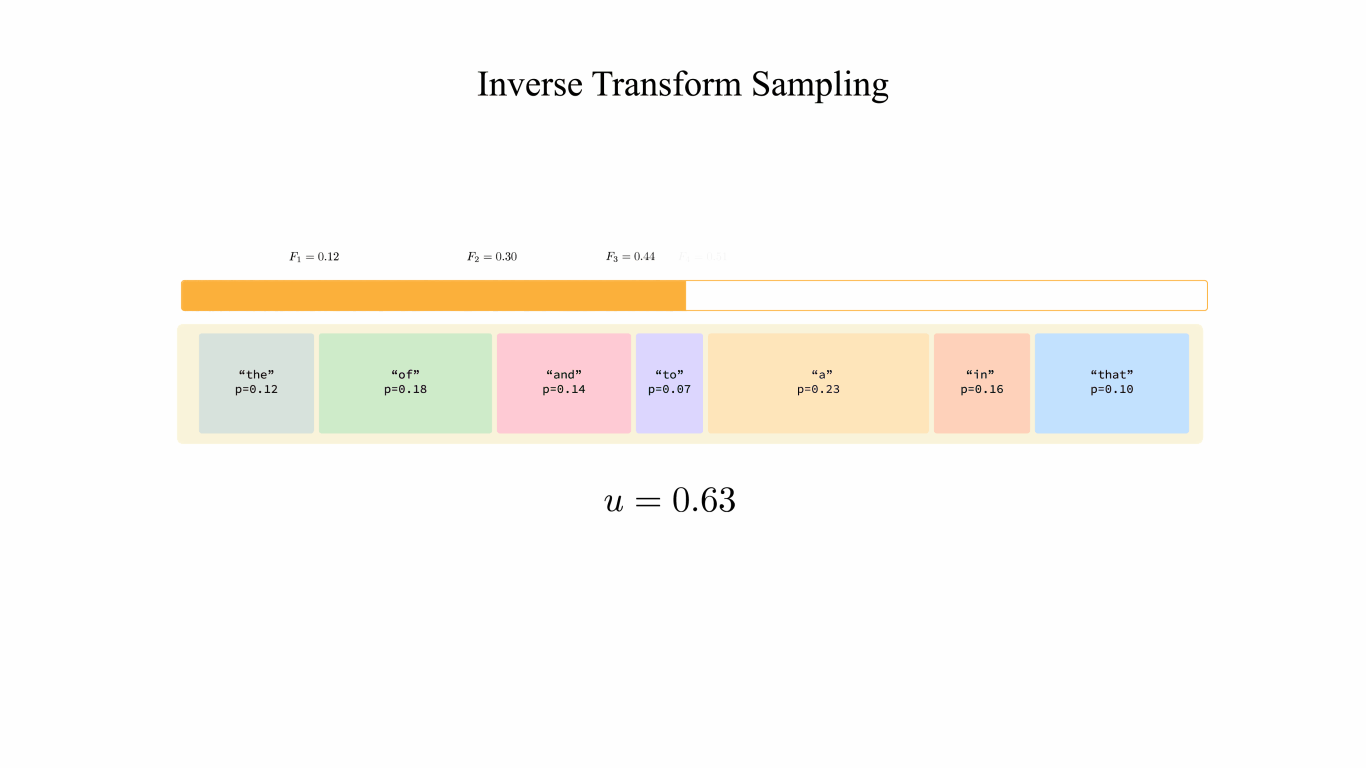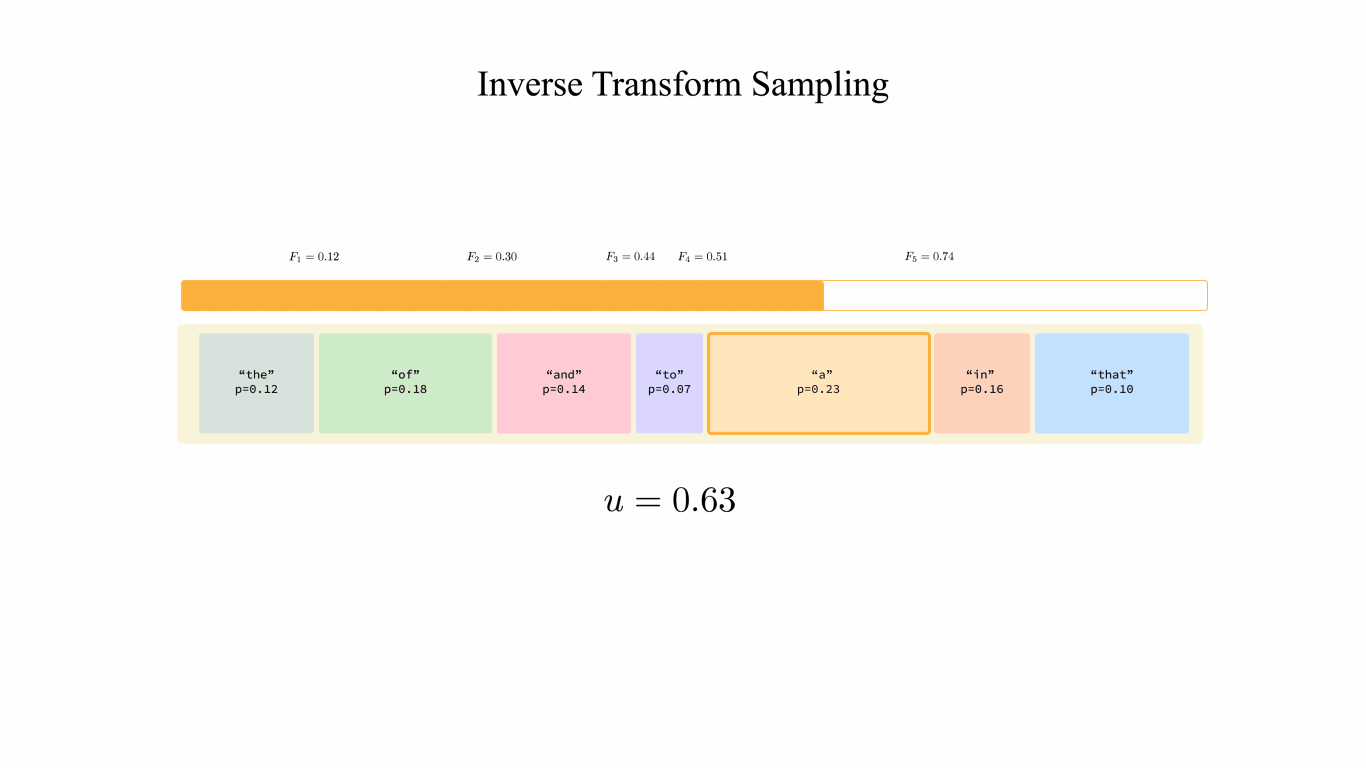
Figure 2: Inverse Transform Sampling. This animation illustrates the per-block process, and in practice the workload gets executed by blocks.
We begin with implementing a basic sampling kernel that selects tokens purely based on their probabilities, particularly in the GPU parallel computing context.
The method is inverse transform sampling, which draws samples from a probability distribution given its cumulative distribution function (CDF). As for the token samling process, the CDF would be the prefix sum of token probabilities. The algorithm proceeds like this:
- Draw a random $u$ from $U\sim \text{Unif}(0,1)$.
- Compute the prefix sums (CDF) for each sampled token $j$ with probability $p_j$: $F_j=\sum^{j}_{i=1}p_i$.
- Locate the token $k$ such that $F_{k-1} \leq u < F_k$ as the result.
NVIDIA’s CUB library (now part of CCCL) provides efficient primitives for parallel computing, and we leverage the reduce and scan primitives to compute the prefix sums. We use one threadblock for each probability distribution, for batch sampling, we launch multiple threadblocks in parallel. Block-level reduce/scan primitives can be applied to a block of elements (BLOCK_SIZE = NUM_THREADS * NUM_ELEMENTS_PER_THREADS, e.g. 1024 * 4 for float input), for vocabulary size greater than BLOCK_SIZE, we split the vocabulary into multiple blocks and sequentially apply the same procedure on each block:
- Initialize a running total $\texttt{a}=0$. Compute the probability sum $\texttt{a_local}$ for each block. If $\texttt{a} + \texttt{a_local}> u$, the sampled token lies in this block.
- If not, we add $\texttt{a_local}$ to $\texttt{a}$ and move on to the next block.
- Once we know the correct block, we perform a prefix sum over its tokens to pinpoint the exact token index.
We use BlockReduce and BlockScan for the per-block partial sum and prefix sums, and AdjacentDifference to locate the token index. In practice, we use early-stopping to terminate the inverse transform sampling process when the cumulative probability exceeds the random number $u$, so we don’t need to go through the whole vocabulary for each round.
Rejection Sampling

Figure 3: Top-P Rejection Sampling. This animation illustrates the per-block process, and in practice the workload gets executed by blocks.
For more advanced strategies such as Top-P sampling, we use rejection sampling to restrict which tokens can be selected. Rejection sampling draws from a target distribution by comparing random samples against a threshold and discarding those that do not meet it.
Taking the sampling kernel under Top-P filtering as an example, here is a simplified look of what happens:
- Initialize the pivot to $0$, so initially all tokens are considered.
- Perform an inverse transform sampling pass but ignoring tokens with probabilities below the current pivot. After sampling a token, update the pivot to that token’s probability.
- Compute the remaining probability $\texttt{q}$ among tokens that still exceed this pivot:
- If $\texttt{q}$ remains greater than or equal to $\texttt{top_p}$, another round is needed to raise the pivot further and reject more tokens.
- Otherwise, if it is below $\texttt{top_p}$, we finalize the sampled token and mark success.
- Repeat until successful.
The whole algorithm can be implemented in a single fused kernel, and it works similar for Top-K and other filtering strategies, other than we’ll be checking the number of tokens exceeding the pivot against $\texttt{top_k}$ or $\texttt{min_p}$.
In practice, we find that the number of rounds for returning a sampled token is usually small. It provides a substantial speedup compared to the naive PyTorch implementation because we avoid the sorting and multiple passes over the vocabulary, as well as multiple kernel launch overheads.
Dual Pivot Rejection Sampling
While this rejection sampling approach is simple and efficient in most cases, it has some limitations. There is no theoretical guarantee on the number of rounds needed to obtain a sampled token. This can lead to varying sampling times across different probability distributions, which in turn causes inconsistent inter-token latency during LLM inference serving. Such variability may impact the predictability and reliability of the serving system.
To address this issue, in FlashInfer v0.2.3, we introduce the a new algorithm called Dual Pivot Rejection Sampling, which uses two pivots for faster convergence in rejection sampling. The algorithm is as follows:
- Let $f$ be a function that checks if a probability value is valid: $f(x)=1$ if valid, $0$ if not.
- Initialize $\textrm{low} \leftarrow 0$ and $\textrm{high} \leftarrow \max_i(p_i)$ as the initial range, it’s guaranteed that $f(\textrm{low})=0$ and $f(\textrm{high})=1$.
- Sample over probability values in the range $(\textrm{low}, \infty)$ using inverse transform sampling.
- Suppose $j$ is the sampled token, let $\textrm{pivot}_1\leftarrow p_j$, and $\textrm{pivot}_2\leftarrow \frac{\textrm{pivot}_1+\textrm{high}}{2}$.
- If $f(\textrm{pivot}_1)=1$, we accept the sampled token and return $j$.
- If $f(\textrm{pivot}_1)=0$, $f(\textrm{pivot}_2)=1$, we set $\textrm{pivot}_1$ as new $\textrm{low}$ and $\textrm{pivot}_2$ as new $\textrm{high}$.
- If $f(\textrm{pivot}_1)=0$, $f(\textrm{pivot}_2)=0$, we set $\textrm{pivot}_2$ as new $\textrm{low}$.
- Repeat step 3 and 4 until success.

Figure 4: Transition from round(i) to round(i+1) in Dual Pivot Rejection Sampling, we either accept the sampled token (case 1) or shrinking the range by at least half (case 2 and 3).
Figure 4 shows the transition from round(i) to round(i+1) in Dual Pivot Rejection Sampling, in each round, if the sampled token is accepted, we return the token, otherwise, the new range’s extent is $\frac{\text{high}-\text{pivot}_1}{2} < \frac{\text{high}-\text{low}}{2}$, which is at least half of the previous range. Thus it’s guaranteed that the number of rounds is $O(\log(1/\epsilon))$ where $\epsilon$ is the minimal possible value in floating point representation.
Theoretical Proof of the Correctness of Rejection Sampler
In this section, we provide a theoretical proof of the correctness of the rejection sampler, we choose the top-k sampling as an example, and other samplers can be proved in a similar way.
Nomenclature
| Symbol | Meaning |
|---|---|
| $p_i > 0$ | Un‑normalised score (unnormalised probability mass) of item $i$ |
| $T = \operatorname{Top}k = {i_1,\dots,i_k}$ | Indices of the k largest scores |
| $Z = \sum_{j \in T} p_j$ | Total mass of the top‑k items |
| $\tau$ | Current pivot (threshold) value |
Theorem
The algorithm outputs each top‑k index $j \in T$ with probability
\[\Pr[\text{output}=j] \;=\; \frac{p_j}{Z},\]i.e. exactly the distribution obtained by first discarding all non‑top‑k items and then sampling categorically inside the top‑k set.
Proof
Fix any pivot $\tau < \min_{j \in T} p_j$ (true at every step because $\tau$ is always taken from a rejected non‑top‑k item). Define
\[Q_j(\tau) \;=\; \Pr[\text{algorithm eventually returns } j \mid \text{current pivot } \tau], \quad j \in T .\]With
\[S(\tau) \;=\; \sum_{m : p_m > \tau} p_m \;=\; Z \;+\; W(\tau),\qquad W(\tau) \;=\!\!\!\! \sum_{r \notin T,\, p_r > \tau}\!\!\!\! p_r ,\]where $S(\tau)$ is the sum of all the probabilities of the tokens that are greater than $\tau$, and $W(\tau)$ is the remaining mass of “bad” items still above the threshold.
The next draw obeys
\[\Pr[i \mid \tau] \;=\; \frac{p_i}{S(\tau)}.\]Hence
\[Q_j(\tau) \;=\; \underbrace{\frac{p_j}{S(\tau)}}_{\text{accept immediately}} \;+\; \sum_{\substack{r \notin T \\ p_r > \tau}} \underbrace{\frac{p_r}{S(\tau)}}_{\text{draw } r}\; \underbrace{Q_j\!\bigl(p_r\bigr)}_{\text{pivot becomes } p_r} \tag{★}\]We show that the following formula is a valid solution to (★):
\[\boxed{\,Q_j(\tau) \;=\; \dfrac{p_j}{Z}\,} \qquad\text{for every }\tau < \min_{j \in T} p_j .\]We can verify the solution by substituting it into (★):
\[\begin{aligned} \text{RHS} &= \frac{p_j}{S(\tau)} \;+\; \frac{p_j}{Z} \frac{W(\tau)}{S(\tau)} \\ &= \frac{p_j}{S(\tau)}\!\Bigl(1+\frac{W(\tau)}{Z}\Bigr) \\ &= \frac{p_j}{Z} \frac{Z+W(\tau)}{S(\tau)} \\ &= \frac{p_j}{Z}, \end{aligned}\]because $S(\tau) = Z + W(\tau)$. Thus the claimed form satisfies the recurrence, so $Q_j(\tau) \equiv p_j/Z$.
Now let’s show that the solution is unique. Suppose there is another solution $Q_j’(\tau)$ satisfies (★), let’s define $\Delta_j(\tau) = Q_j(\tau) - Q_j’(\tau)$, we have:
\[\Delta_j(\tau) = \sum_{\substack{r \notin T \\ p_r > \tau}} \frac{p_r}{S(\tau)} \Delta_j(p_r)\]The sum of the coefficient $\sum_{\substack{r \notin T \ p_r > \tau}} \frac{p_r}{S(\tau)} = \frac{W(\tau)}{S(\tau)}$, which satisfies:
\[0 \leq \frac{W(\tau)}{S(\tau)} < 1\]Suppose $\tau^*$ is the pivot where \(|\Delta_j(\tau)|\) reach its maximum, if it’s positive, we have:
\[|\Delta_j(\tau^*)| \leq \sum_{\substack{r \notin T \\ p_r > \tau^*}} \frac{p_r}{S(\tau)} |\Delta_j(p_r)| \leq \sum_{\substack{r \notin T \\ p_r > \tau^*}} \frac{p_r}{S(\tau)} |\Delta_j(\tau^*)| = \frac{W(\tau^*)}{S(\tau^*)} |\Delta_j(\tau^*)| < |\Delta_j(\tau^*)|\]which leads to a contradiction, which means $\Delta_j(\tau^*) = 0$, and our solution is unique.
The algorithm starts with $\tau = 0$; therefore
\[\Pr[\text{output}=j] = Q_j(0) = \frac{p_j}{Z},\]exactly the desired top‑k categorical distribution.
Evaluation
Our evaluation demonstrates that FlashInfer’s sampling kernel delivers substantial improvements in both kernel-level latency and end-to-end throughput compared to traditional sorting-based implementations.

Figure 5: Throughput Comparison of Different Engine Kernel.

Figure 6: Sampling Latency Growth with Batch Size.
Community Adoption and Other Applications
The FlashInfer sampling kernel has gained widespread adoption across major LLM frameworks, including MLC-LLM, sglang, and vLLM. The community’s active engagement through feedback and bug reports has been instrumental in refining and improving our implementation.
Beyond token sampling, the rejection sampling algorithm have proven valuable in other areas of LLM inference optimization. Similar algorithm can also be applied to speculative decoding verification, like chain speculative sampling and tree speculative sampling. Recent innovations like Twilight have further advanced the field by successfully combining top-p sampling with sparse attention in a unified approach.
Implementation Details
While the algorithm is elegant in theory, implementing it efficiently in a GPU kernel requires careful attention to detail, particularly in the token selection logic in inverse transform sampling. One key challenge lies in the parallel prefix-sum operation used to locate sampled tokens. Due to the non-associative and non-commutative nature of floating-point arithmetic, parallel prefix-sum cannot guarantee monotonic outputs even with non-negative inputs. This can lead to invalid token generation if not handled properly. Special care must be taken to ensure numerical stability and correctness in the sampling implementation (and we made a lot of mistakes before got it right)
For a detailed look at our implementation and how we tackle these challenges, you can explore our source code. Additionally, FlashInfer offers a comprehensive set of APIs for probability cutoff and renormalization, such as top_p_renorm_probs and top_k_renorm_probs, enabling flexible composition of multiple sampling filters. These tools allow developers to build sophisticated sampling strategies tailored to their specific needs.
Acknowledgement
This blog is written by Shanli Xing, we thank the flashinfer team for their contributions to the flashinfer.sampling module:
- Zihao Ye: design and implementation of sampling kernels in CUDA.
- Bohan Hou: design and implementation of sampling kernels in TVM.
- Shanli Xing: design and implementation of min-p sampling kernels in CUDA.
- Tianqi Chen: propose the idea of rejection sampling for top-p.
Comments