
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems
| Leaderboard | FlashInfer Trace | GitHub |
Have you ever imagined an AI system that improves itself?
—Not exactly the machine overlords from sci-fi, but still, an AI system that can expand its capabilities using AI itself sounds pretty cool.
—And it is something we’re building: FlashInfer-Bench—a benchmark and infrastructure that opens the pathway for AI to accelerate real-world AI deployment.
AI agents have become remarkably powerful, capable of writing complex code and even building sophisticated systems. Such powerful capabilities naturally lead us to wonder: can AI agents optimize the very production systems they run on? At the heart of these AI systems, the most intensive parts are GPU kernels—the low-level programs that perform the core operations for AI models. We have seen amazing progress recently that shows LLMs can generate reasonable GPU kernels (https://scalingintelligence.stanford.edu/blogs/kernelbench/).
That prompts us to ask the next natural question: how can we systematically get AI agents to improve the very AI system they depend on? We know there can still be hurdles towards this ultimate dream, but it is time to get ready to build a clear pathway for the future. We build FlashInfer-Bench, a benchmark of real-world AI-system driven GPU workloads, and more importantly, an infrastructure and workflow to 0-day ship AI-generated kernels into production. While the AI today may not yet perform at the expert engineer level, we would like to get our infrastructure ready and open the pathway to accelerate this ultimate goal. The same workflow would also benefit machine learning system engineering in general, helping us to build and evolve next-generation kernel libraries.

Overview: Systematically Approaching AI for AI Systems
As we approach the goal for “AI for AI systems”, we naturally find that we need more than just benchmarks. Real-world production environments are highly complex: they involve a large number of sophisticated kernels with different API designs and input signatures, while each kernel’s performance can also vary depending on the input it receives. We need to clearly communicate these needs to AI agents and relevant engineers; more importantly, we also need to be able to quickly adopt the solutions from agents back onto production. Fundamentally, we need to consider the following three elements to systematically approach our problem:
- Clarify the landscape. We need a standardized way to describe the workloads, including their inputs and outputs, along with relevant statistics and characteristics (e.g., shape, raggedness, etc.)
- Set the right goal. We need benchmarks that capture real-world, production-grade workloads—in other words, the scenarios that occur when LLMs are deployed in practice.
- Establish a day-0 production path. AI-generated and human-written code can be seamlessly deployed into a real LLM engine right away with as little intervention as possible.
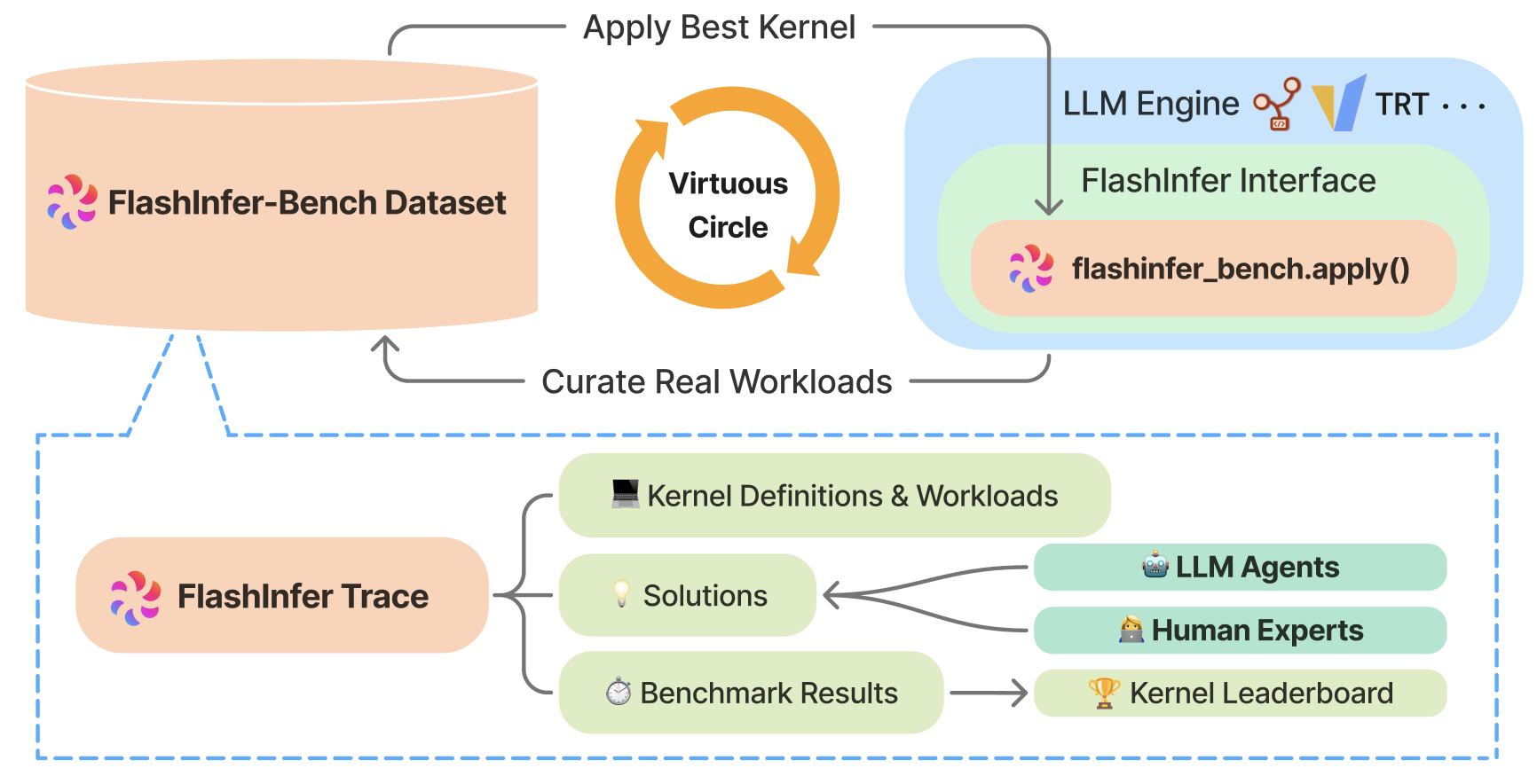
FlashInfer-Bench is designed specifically to address these three challenges. As illustrated in the architecture diagram above, its core components work as follows:
-
Clarify the landscape — FlashInfer Trace. To formalize the description of GPU workloads, we developed FlashInfer Trace: a systematic and evolving open schema that captures the kernel definitions, implementation, and evaluation in LLM inference scenarios. This format addresses the critical needs through four key components: kernel definition that defines the kernel signature and computation; workload that describes the kernel’s real inputs; solution to the kernel; and the solution’s evaluation results.
-
Set the right goal — FlashInfer-Bench Dataset. We collected and curated the most important kernels used in production, along with their real workloads, to create a dataset. This allows us to measure kernel performance under real traffic conditions and further makes it possible to concretely improve production systems.
-
Establish a 0-day production path — First-class FlashInfer Integration. We build first-class integration with FlashInfer — an open LLM kernel library widely used in major LLM inference engines. Our solution can dynamically replace the FlashInfer Kernels with the best-performing kernels, as evaluated using the FlashInfer Trace and the FlashInfer-Bench dataset. This enables activating the best kernels in LLM engines and testing end-to-end performance with minimal effort.
In the rest of the post, we will walk through the details about the three main elements.
FlashInfer Trace: Standardizing and Evolving Schema for LLM Kernels

As discussed in the overview section, we need a standard way for humans, infrastructure workflows, and AI agents to communicate about the context throughout the overall production life cycle. We specifically would need to support different stages in the production lifecycle, including handling the problem to the agent/engineers, recording the answer, evaluating, and inspecting the outputs.
We define FlashInfer Trace, a set of JSON schemas to formally describe a kernel’s definition, benchmark workload, solution, and evaluation results. Below is the figure showing FlashInfer Trace’s components:
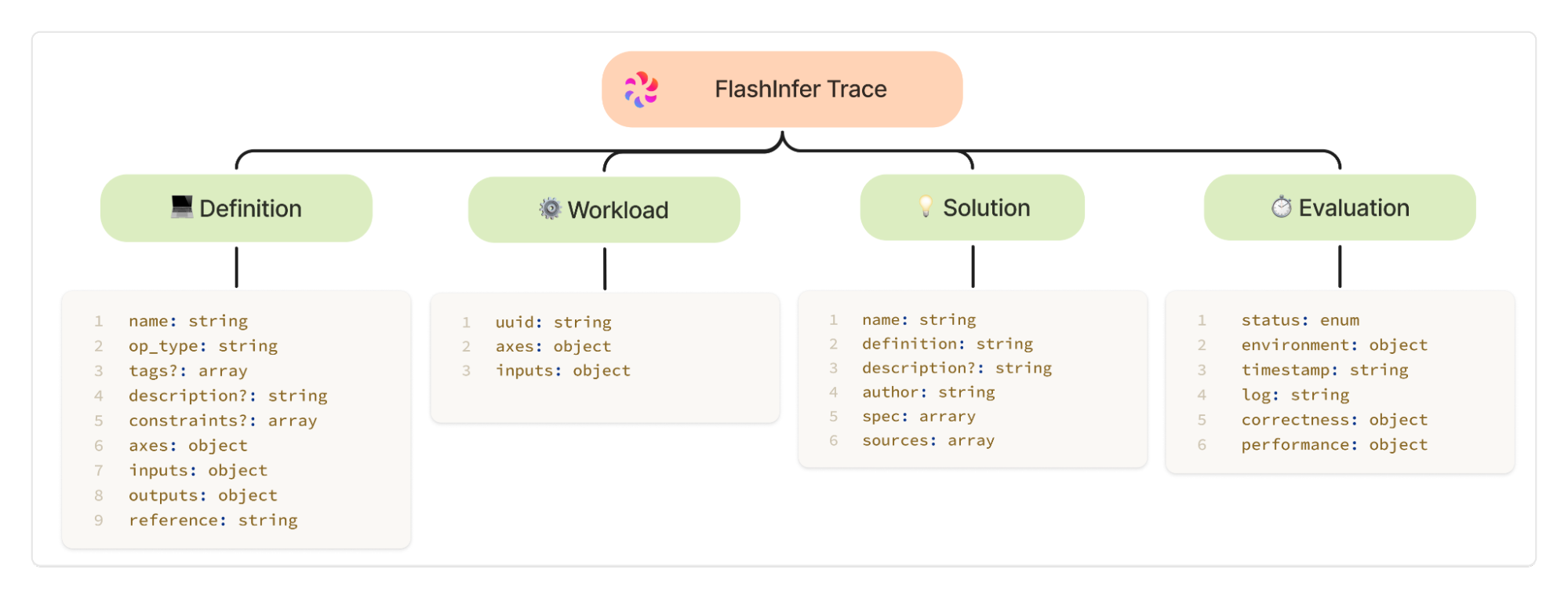
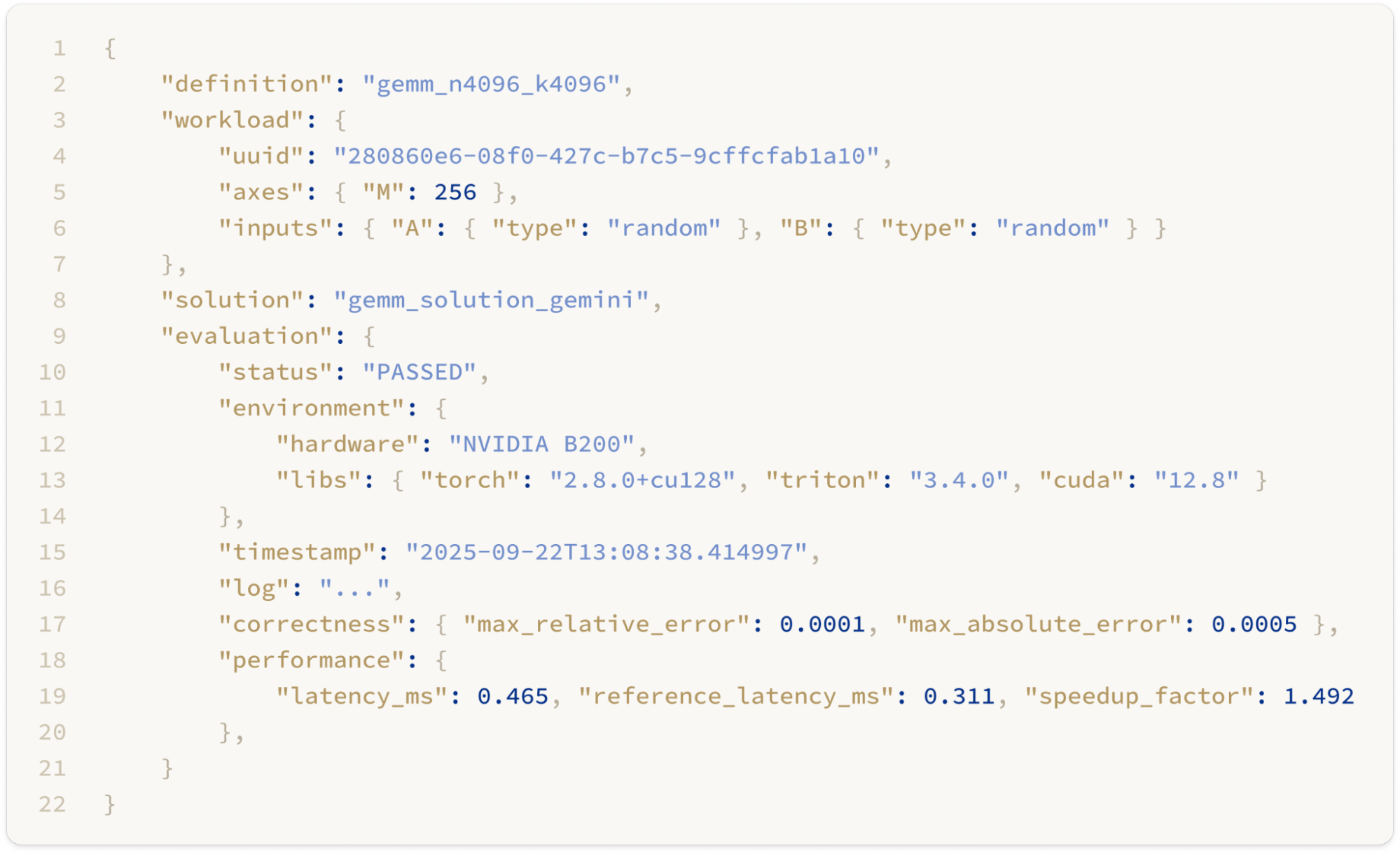
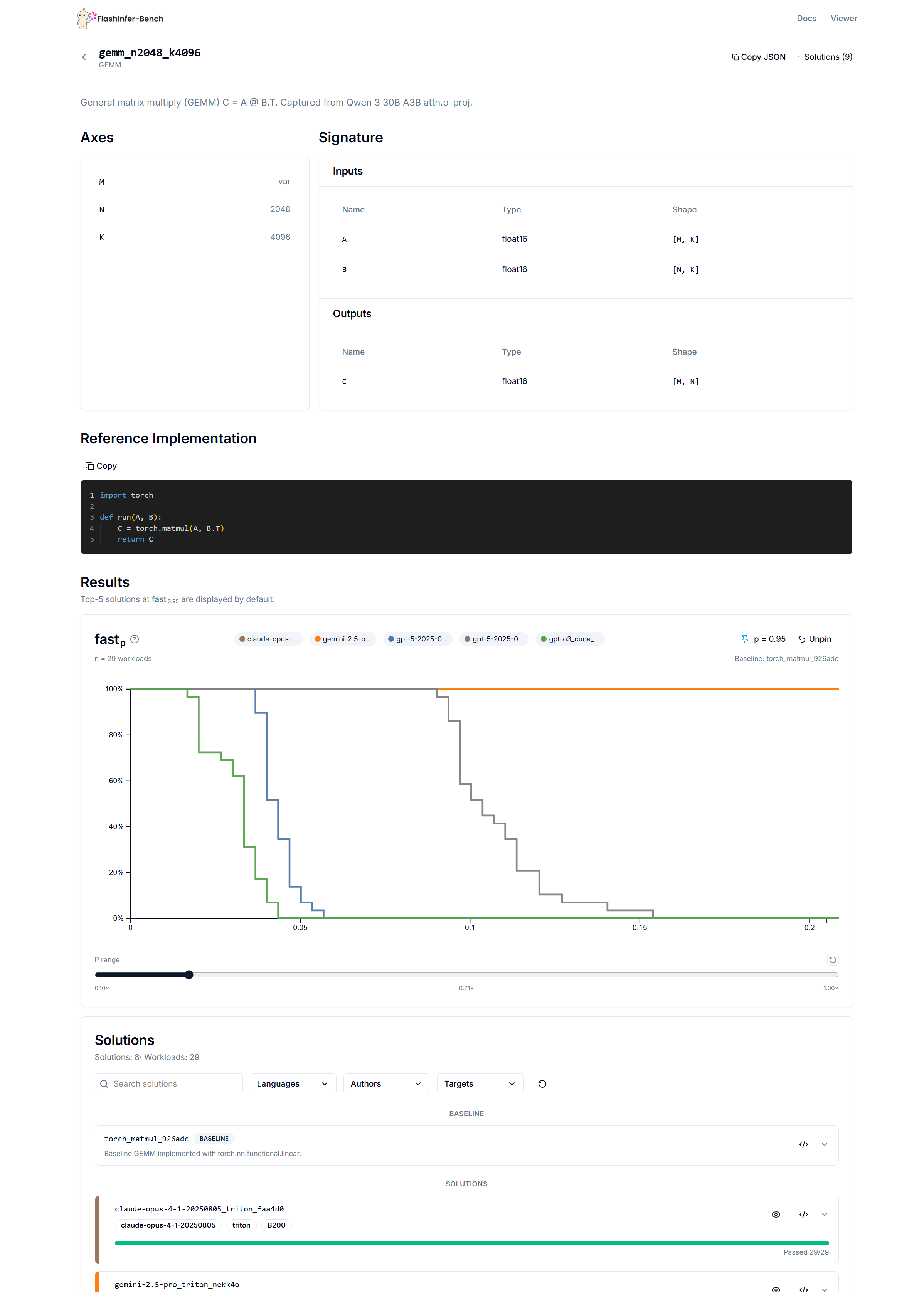
Definition provides the complete specification of the kernel, including the kernel metadata, input and output specifications, axes of input and output tensors, and a reference implementation written in Python, defining the kernel’s computational behavior. The kernel definition provides all the information needed for AI to generate kernels. This is an example of a General Matmul (GEMM) kernel definition:

In the kernel definition, we aim to capture as many details of a kernel as possible, especially the constant axes value. This is because kernels with different input shapes often require different optimal implementations. For example, a GEMM with a dimension of 4096 may have a very different implementation from one with a dimension of 128. Some axes in AI systems are dynamic, such as the sequence length. These dimensions will be kept variable so that the workload can provide its concrete values.
We also design the op_type that specifies input and output and computation at a high level, such as GEMM (as gemm) and Paged Grouped-Query Attention (as gqa_paged). By defining op_type, we can group together multiple kernel definitions that have different axes but share similar computation. We define op_types for common LLM operators, and we aim to evolve this standard with the community.
Workload captures the kernel’s inputs observed in real traffic, including both tensor inputs and scalar or flag inputs. If the specific values of a tensor do not affect evaluation, it can be stored as random to save space; otherwise, the original tensor can be dumped to reproduce the most realistic production scenario.

Solution gives the concrete implementation of a kernel. It must perform the same computation as the reference in the kernel definition. We support multiple kernel programming languages, including CUDA, Triton, Python, and TVM (coming soon!), among others. We can also specify the kernel’s author, target hardware, compatible software versions, and other related information.

Evaluation is the benchmark result for a specified solution on a certain definition and workload. The hardware and software used for evaluation, as well as the kernel’s correctness and runtime performance, are fully measured. When a kernel fails to compile or has a runtime error, we assign different evaluation statuses accordingly.
With the standardized design of the FlashInfer Trace, we can easily exchange information throughout the production lifecycle:
- Workload tracer can take traffic from an LLM inference engine and produce workload traces;
- AI agents can then take the definition to further generate a kernel solution;
- Benchmark tools can take the workload and solution and fill in the evaluation field;
- The leaderboard will take a collection of traces and visualize the result.
We built the flashinfer-bench Python package following this philosophy, which contains support to work with FlashInfer trace and tooling across various stages, including schema validation, benchmarking, workload tracing, and integration with LLM engine and FlashInfer. The design of the FlashInfer Trace is independent of specific tools, and we encourage the community to develop a more versatile toolchain.
Real CUDA engineers can also benefit from the FlashInfer Trace. It standardizes kernel interfaces and computations, reducing communication overhead and enabling fair comparison across kernels from different sources. It provides testing tools to measure the performance of kernels and tracing tools to easily capture real workloads. Altogether, these greatly simplify the burden of kernel development.
We provide standardized and clear documents for FlashInfer Trace and Op Types.
Dataset & Benchmark — The Yardstick from the Real World

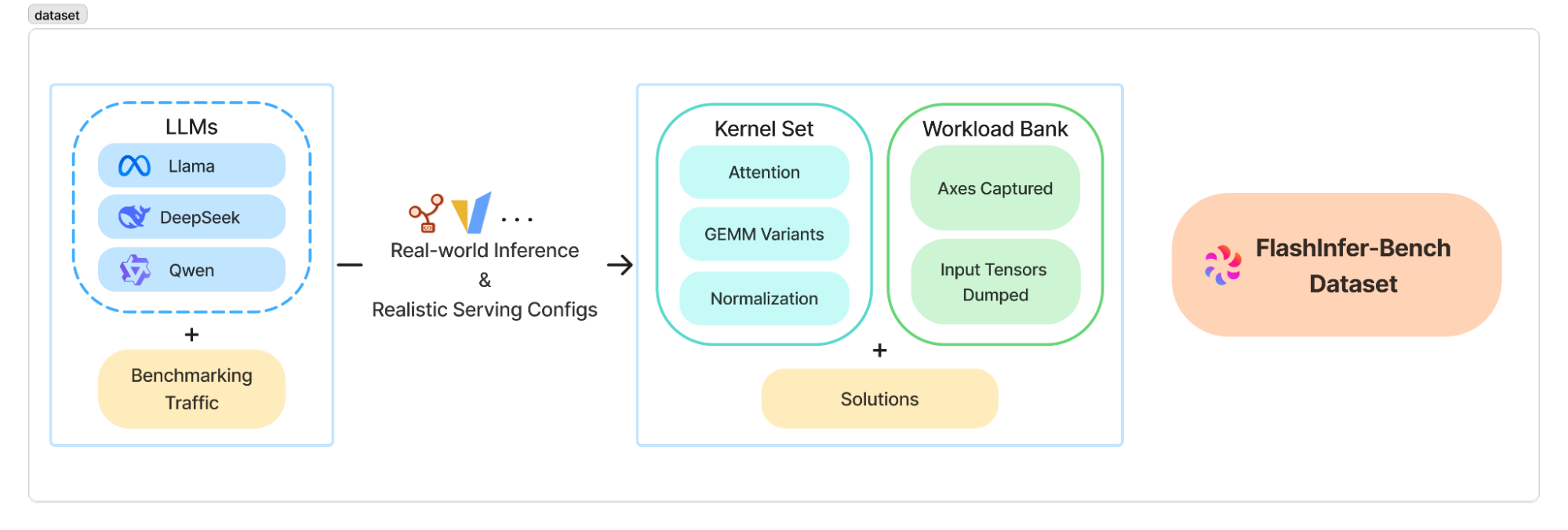
We curate the dataset by one principle: real-world relevance. This means focusing on the most important kernels in the LLM engine and recording their workloads under realistic production traffic. We selected the most popular models, including Llama 3, DeepSeek V3, and Qwen 3, and recorded their main kernels, including attention, GEMM, MoE, normalization, sampling, and more. We also strive to ensure realism in the LLM engine configuration. For example, for DeepSeek-V3, we use the original FP8 quantization and enable tensor parallelism = 8 and expert parallelism = 8. We feed inputs from real datasets, including ShareGPT and more. These ensure that the workloads we measure are as close to real-world scenarios as possible.
Day-Zero Integration Through FlashInfer

The final step of the virtuous cycle is getting AI-generated kernels into production immediately. We achieve this by first-class integration with FlashInfer, a well-adopted kernel library by major LLM engines, and SGLang. Integration with vLLM is also progressing rapidly and is expected to be completed soon.
We can dynamically replace the kernels in the FlashInfer API with the best-performing ones from our evaluations, all with minimal effort. By simply importing flashinfer_bench in the LLM engine and enabling the environment variable FIB_ENABLE_APPLY, the kernels can be automatically replaced with the best ones from the local database.
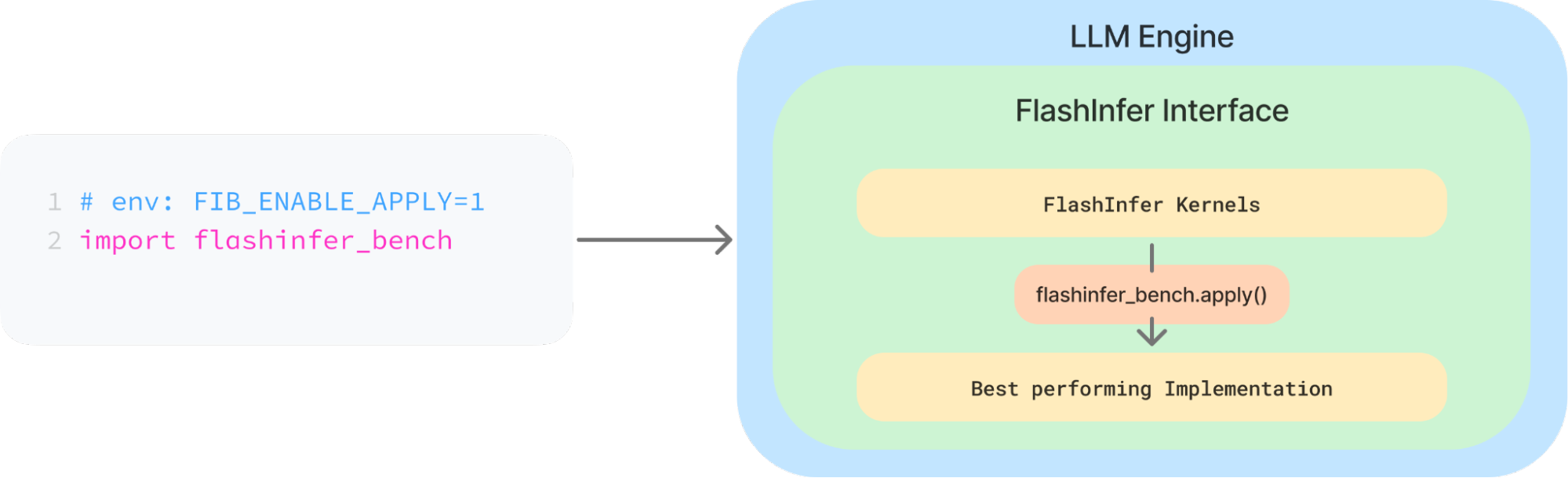
Under the hood, the dynamic substitution is supported by the flashinfer_bench.apply() decorator:
@apply(lambda A, B: f"gemm_n_{B.shape[0]}_k_{B.shape[1]}")
def gemm_bf16(
A: torch.Tensor,
B: torch.Tensor,
) -> torch.Tensor:
# Fallback Implementation
return torch.matmul(A, B)
It takes a lambda function that maps the inputs to a specific kernel definition name, then replaces the original computation function. The replaced function filters the best-performing kernel solution from the database based on the inputs, executes it, and returns its result. If no matching kernel solution is found, the original function runs as a fallback.
By using apply(), we can replace a large number of operators in FlashInfer. If you want to replace operators from your own implementations or other libraries, you can also easily achieve this with apply().
FlashInfer-Bench Leaderboard — The Arena for LLM Kernel Optimization
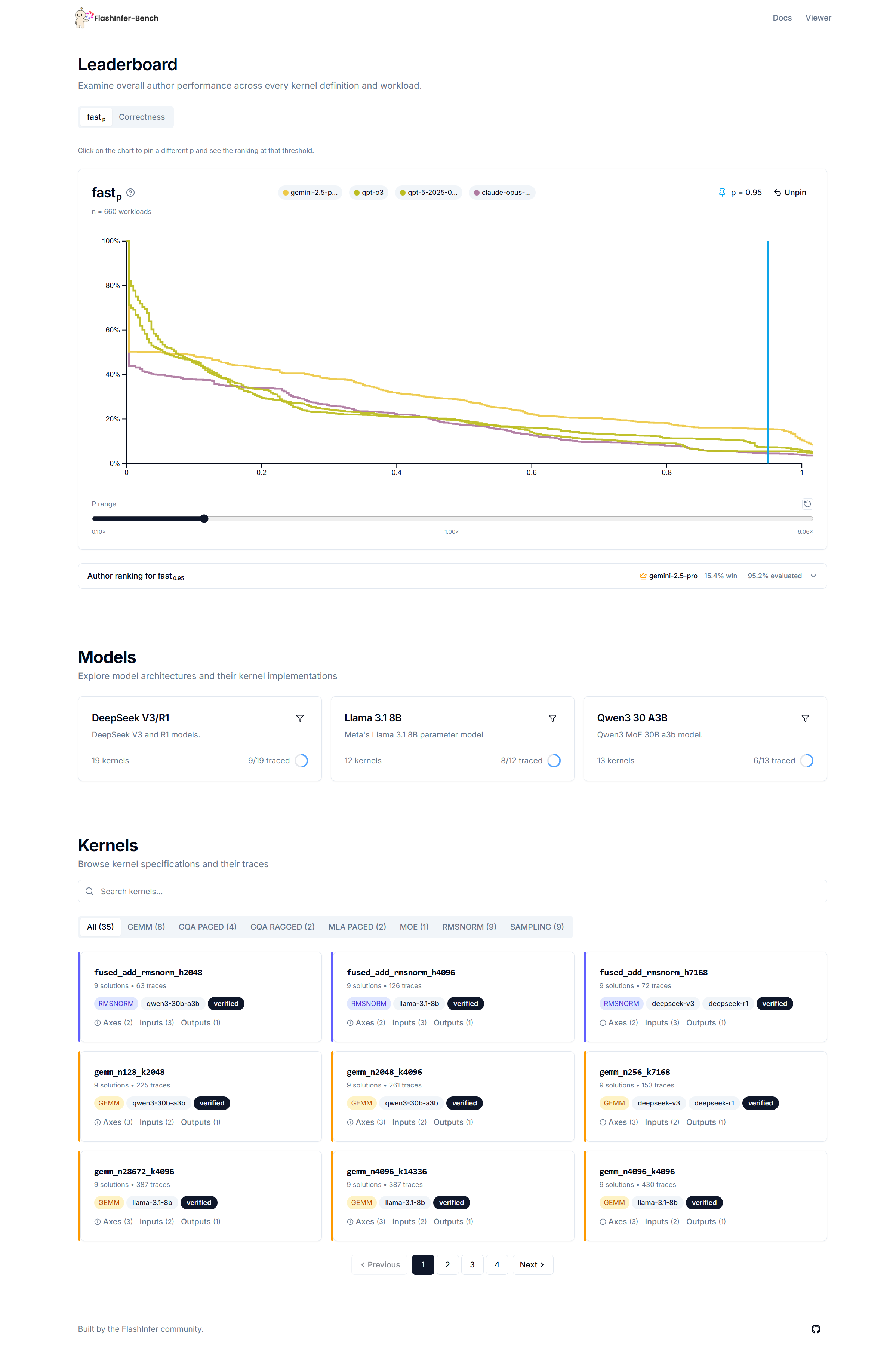
FlashInfer-Bench provides a standardized benchmark for AI agents to improve AI systems. Therefore, we also evaluated the capabilities of different models and built the FlashInfer-Bench Leaderboard. It directly leverages the FlashInfer Trace generated from the benchmark suite and provides a visualized display of the results.
We adopt the \(\text{fast}_p\) metric initially proposed by KernelBench to compare the performance of different kernels. We use the FlashInfer kernel as the baseline for comparison. \(\text{fast}_p\) represents the proportion of workloads on which a given kernel runs p times faster than FlashInfer. If p > 1, it means we have discovered a kernel that outperforms the state-of-the-art kernel library! In practice, most kernels have p < 1, indicating that current models still have significant room for improvement. For different values of p, \(\text{fast}_p\) forms a curve. The larger the area under the curve, the better the kernel’s performance.
We also found a small number of AI-generated kernels with a speedup greater than 1. We deeply understand the importance of ensuring the correctness of kernel implementations, so we are manually verifying the correctness of each kernel. We will soon release kernels with a speedup ratio greater than 1 after review.
We also provide a separate leaderboard for each kernel to make it easier to select the best implementation for each one. The leaderboard also allows further filtering by workload to select the best-performing kernels for specific workloads.
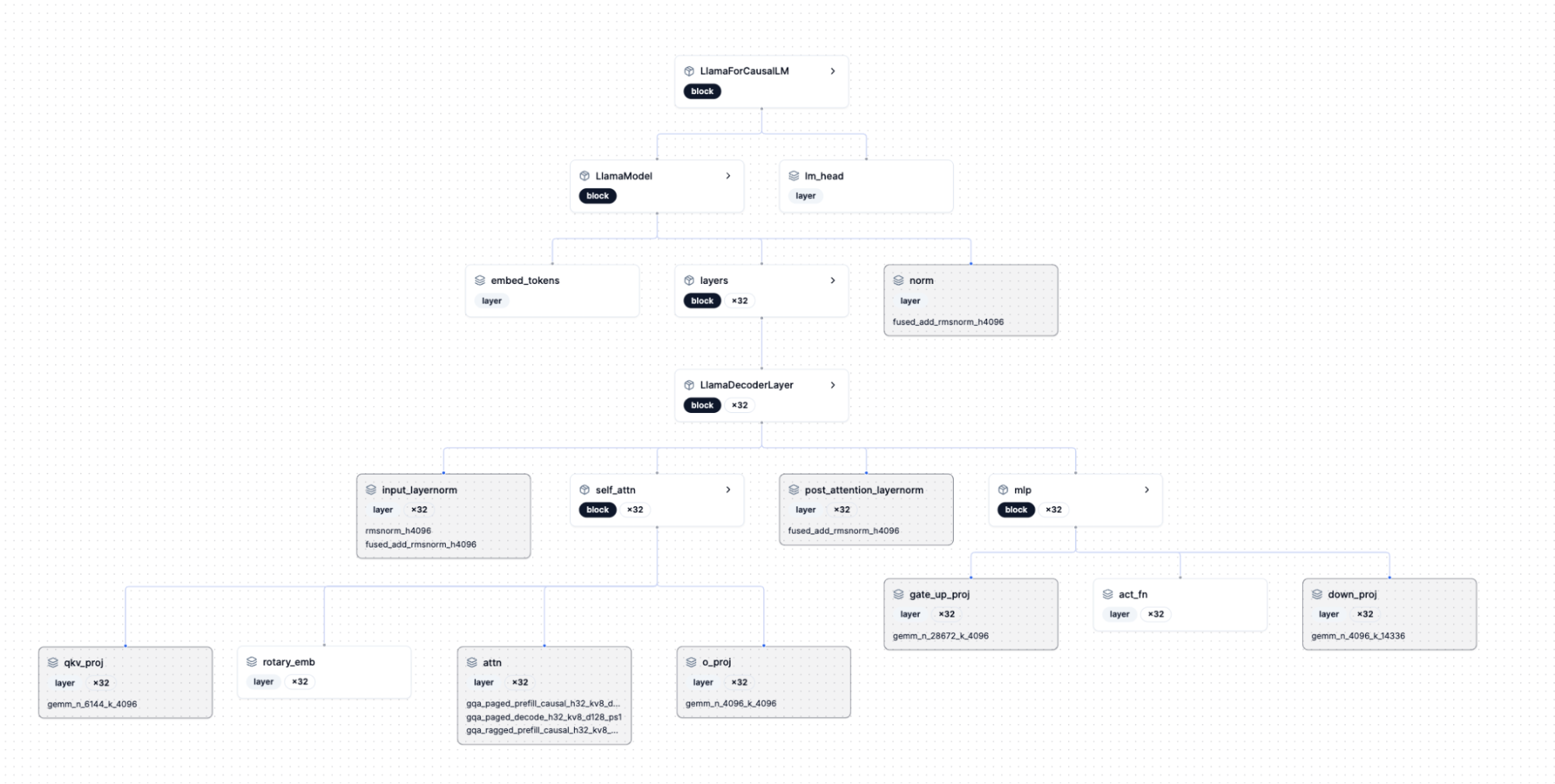
Furthermore, the model architecture overview shows all the kernels used by the model and indicates which ones are already covered by FlashInfer-Bench:
Summary
FlashInfer-Bench provides a systematic solution for building AI that improves AI systems. With it, we have already built a self-optimizing loop for AI—a virtuous cycle. The revolution of AI improving itself will continue—let’s see where it goes!
Looking ahead, we plan to continually expand our coverage of models and kernels. We will collaborate closely with GPU engineers and LLM engine developers to adapt to the fast-evolving needs of the field. This journey is a community effort, and we welcome your discussions and contributions.
For more information, please visit the following links:
Acknowledgements
FlashInfer-Bench is a research effort initiated in collaboration with CMU Catalyst, NVIDIA, and Bosch. We are bringing up an open community as part of the FlashInfer community and welcome contributions from the ML systems community.
We thank the entire FlashInfer-Bench team for their contributions to the project:
- Shanli Xing* (UW, CMU): Core components and web development
- Yiyan Zhai* (CMU): FlashInfer-Trace dataset, workload tracing system
- Alexander Jiang* (CMU): Benchmark system, agent design
- Yixin Dong* (CMU): Core idea, overall architecture design
- Yong Wu (NVIDIA): RMSNorm, sampling, fused MOE
- Zihao Ye (NVIDIA): FlashInfer support
- Charlie Ruan (UC Berkeley): Workload tracing system
- Yingyi Huang (CMU): Fused MOE
- Yineng Zhang (Independent researcher): SGLang integration
- Liangsheng Yin (Independent researcher): SGLang integration
- Aksara Bayyapu (CMU): LLM agents
- Luis Ceze (UW, NVIDIA): Project guidance and advice
- Tianqi Chen (CMU, NVIDIA): Project guidance and advice
We would also like to thank Mark Saroufim, Zhuoming Chen, Weihua Du, Bohan Hou, Hongyi Jin, Ruihang Lai, Xinyu Yang, Yilong Zhao, Haizhong Zheng, the FlashInfer community, the GPUMODE community, the HuggingFace community, the SGLang community, the TensorRT-LLM community, the vLLM community, Databricks, and xAI for their insightful feedback.
Comments